Introduction
Picture this: You’re deep into a project that requires AI assistance, toggling between ChatGPT for code, Claude for document analysis, and Gemini for long-context research. Three browser tabs. Three separate logins. Three monthly bills totaling over $110. Sound familiar?
The multimodal LLM landscape in 2025 has evolved dramatically. These AI models now process text, images, audio, video, and code within unified systems—handling up to 10 million tokens of mixed-modality input. GPT-5 achieves mid-80% accuracy on college-level visual reasoning benchmarks, while Gemini 1.5 Pro can analyze entire books and multi-hour videos in a single conversation.
But here’s the challenge: Each premium model excels at different tasks. GPT-5 dominates reasoning and code. Claude handles sensitive content with unmatched nuance. Gemini crushes long-context analysis. To access all these strengths, professionals have been forced to maintain multiple expensive subscriptions.
SimpleChat changes this equation entirely. The platform provides access to 10+ premium multimodal models—including GPT-5, Claude 4.1 Opus, Gemini 2.5 Pro, Grok 4, and Perplexity Sonar—through one unified interface at approximately 90% lower cost than separate subscriptions. Over 12,500 professionals already use it to streamline their AI workflows and save roughly $1,188 per year.
In this guide, we’ve tested and ranked the best multimodal LLM solutions in 2025 based on capabilities, real-world performance, pricing, and practical use cases. Whether you need an all-in-one platform, cutting-edge reasoning, safety-critical applications, or open-source flexibility for local deployment, you’ll find the right solution below.
Let’s dive into the rankings.
Understanding Multimodal LLMs in 2025
Multimodal LLMs are AI systems that process and generate content across multiple formats—text, images, audio, video, and code—within a single unified model. Unlike traditional language models limited to text, these systems understand relationships between different data types, enabling them to analyze charts in documents, generate code from screenshots, or extract insights from video content.
Why 2025 Marks the Multimodal Breakthrough
The capabilities have reached practical enterprise levels. GPT-5 now scores in the mid-80% range on MMMU (Massive Multi-discipline Multimodal Understanding), a benchmark testing college-level visual reasoning across subjects from physics to art history. Gemini 1.5 Pro handles context windows approaching 10 million tokens, meaning you can feed it entire codebases, multi-hour video transcripts, or dozens of research papers simultaneously.
Open-source options like LLaMA 3.2 democratized these capabilities further. You can now run competent multimodal models locally on Apple Silicon Macs, bringing vision-language understanding to on-premise environments without cloud dependencies.
Key Capabilities That Define Multimodal Excellence
Document intelligence: Modern multimodal LLMs extract insights from PDFs, spreadsheets, presentations, and scanned documents while understanding layout, tables, charts, and embedded images. They don’t just read text—they comprehend visual structure and data relationships.
Code understanding with visual context: These models analyze code alongside architecture diagrams, UI mockups, and error screenshots. A developer can share a bug report with stack traces and visual evidence, and the AI provides contextualized debugging suggestions.
Video and audio processing: Meeting recordings, tutorial videos, and podcasts become searchable and analyzable. The AI understands both spoken content and visual elements like slides, demonstrations, or shared screens.
Cross-modal reasoning: The real power emerges when combining modalities. Ask a question about financial data in a PDF, reference a chart from a presentation, and request code to automate similar analysis—all in one conversation thread.
Professionals using multimodal LLMs report consolidating 3-5 specialized tools into streamlined AI workflows. Instead of separate applications for OCR, transcription, code assistance, and document analysis, one capable multimodal system handles everything.
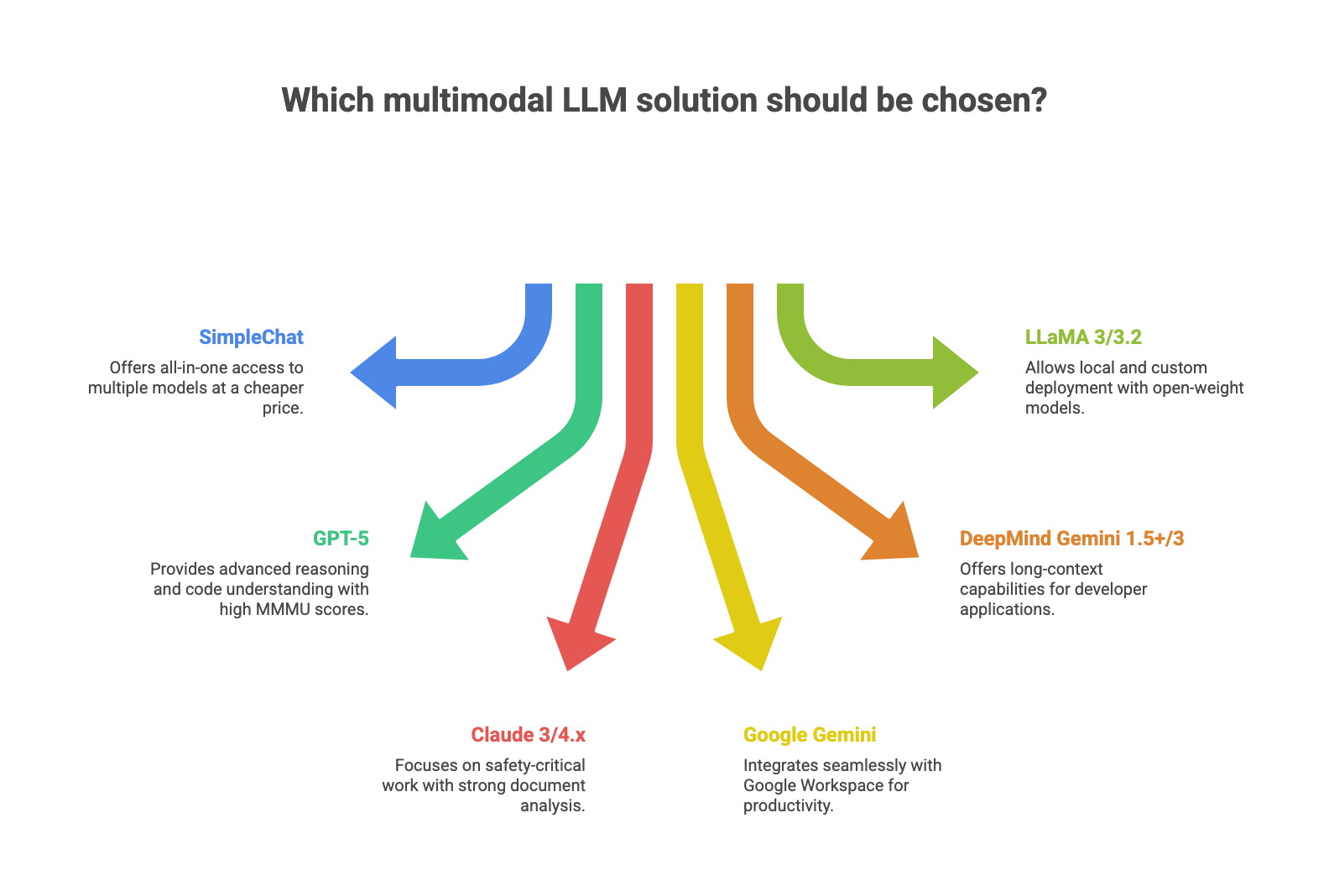
Top 6 Multimodal LLM Solutions (Ranked)
We evaluated these solutions based on multimodal capabilities, model variety, pricing efficiency, ease of use, and real-world performance across document analysis, code generation, image understanding, and video processing tasks. Testing spanned 30+ days with hands-on workflows that professionals actually use. All pricing information has been verified as of November 2025.
1. SimpleChat.app – Best All-in-One Multimodal LLM Platform
SimpleChat is a unified AI platform providing access to 10+ premium multimodal models through a single interface and subscription. Instead of managing multiple accounts and paying $110+/month for separate ChatGPT Plus, Claude Pro, and Gemini Advanced subscriptions, users access all top models in one place. The platform currently serves over 12,500 professionals for daily AI workflows.
Access to 10+ Leading Models
SimpleChat includes GPT-5 and GPT-5 Mini from OpenAI, Claude 4.1 Opus from Anthropic, Gemini 2.5 Pro and Gemini 2.5 Flash from Google, Grok 4 and Grok 3 from xAI, plus Perplexity Sonar and Sonar Pro models. This eliminates the “which model should I use?” dilemma—you can test the same prompt across different models and choose the best output.
Single Unified Interface
Switch between models mid-conversation without losing context or juggling browser tabs. The consistent user experience means you learn one interface instead of navigating different designs across ChatGPT, Claude, and Gemini platforms.
Multi-Model Comparison
Run identical prompts through GPT-5, Claude, and Gemini simultaneously to identify which model handles your specific task best. This comparative testing would cost hundreds of dollars monthly through separate subscriptions.
Cost Efficiency That Actually Matters
Traditional approach costs roughly $110/month when combining ChatGPT Plus ($20), Claude Pro ($20), Gemini Advanced ($20), and other premium subscriptions. SimpleChat consolidates access at approximately 90% lower cost, translating to annual savings of around $1,188 per user.
Pros:
- One tool for all top multimodal models
- Massive cost savings versus separate subscriptions
- No vendor lock-in—use the best model for each task
- Consistent workflow across all models
- Future-proof as new models get added to the platform
Cons:
- Cloud-based platform requiring internet connection
- Fine-grained API-level customization handled by underlying vendors
Best for: Professionals and teams who want access to multiple premium multimodal models without managing separate subscriptions or paying $100+/month.
Start using 10+ multimodal models in one place with SimpleChat →
2. GPT-5 (OpenAI) – Best for Cutting-Edge Multimodal Reasoning
GPT-5 is OpenAI’s flagship 2025 multimodal model, designed as a unified system handling text, images, charts, diagrams, and video frames. It represents a significant leap in multimodal reasoning, achieving mid-80% accuracy on MMMU benchmarks that test college-level visual reasoning across disciplines.
Native Multimodality
Trained jointly on text, images, audio, and video rather than bolting vision capabilities onto a text model. This joint training enables deeper understanding of relationships between visual and textual information.
Extended Context and Advanced Reasoning
The model supports 100K+ token context windows for consumer use, with larger contexts available through API access. Advanced agentic capabilities include mode switching, tool use, and specialized “Thinking” modes for complex reasoning tasks.
Code and Diagram Excellence
GPT-5 excels at understanding code alongside visual context—architecture diagrams, UI mockups, error screenshots, and flowcharts. Developers report strong performance on multi-file code refactoring and debugging tasks that require visual comprehension.
Pricing Structure
Access through ChatGPT Plus/Pro subscriptions at approximately $20/month, or via API with per-token pricing that varies by model variant (GPT-5 vs GPT-5 Mini). Heavy API usage can escalate costs quickly, especially for image and video workloads.
Pros:
- Best-in-class multimodal reasoning for many benchmarks
- Excellent code understanding with visual context
- Rich ecosystem with plugins and third-party integrations
Cons:
- Closed-source and cloud-hosted only
- API costs climb rapidly for heavy usage
Best for: Tasks requiring deep reasoning over code and complex visual diagrams, or workflows needing cutting-edge multimodal performance.
3. Claude 3/4.x (Anthropic) – Best for Safe, Nuanced Multimodal Work
Claude 3 and subsequent 4.x models from Anthropic balance intelligence, safety, and multimodal capabilities suited for sensitive professional workflows. The model family includes Opus (most capable), Sonnet (balanced), and Haiku (fastest), each with strong text and image understanding.
Safety-Forward Design
Built around constitutional AI principles, Claude handles policy-sensitive content, compliance documentation, and nuanced instructions with reduced refusal errors compared to earlier models. The alignment makes it particularly valuable for HR, legal-adjacent, and governance work.
Large Context Windows
Claude 3 models support approximately 200K token context windows, with later 4.x variants potentially extending this further. This enables long document analysis, extensive chat histories, and comprehensive research synthesis without losing context.
Multimodal Document Understanding
Strong at analyzing images and documents while maintaining careful, controlled outputs. The model excels at summarizing complex materials, extracting structured information, and providing detailed analysis of visual content.
Pricing Options
Free plan with limited usage and access to a current Claude model. Pro and Max plans range from $18-20/month for individuals, with Team and Enterprise plans available at higher tiers. API pricing typically runs in the mid-teens of dollars per million input tokens, with higher costs for output.
Pros:
- Excellent balance of reasoning quality and safety for enterprises
- Strong at summarizing and policy-sensitive content
- Good structured analysis capabilities
Cons:
- Not open-source
- Sometimes more conservative in responses due to alignment preferences
Best for: Policy analysis, HR workflows, legal-adjacent tasks, and any work involving sensitive or compliance-critical content.
4. Google Gemini – Best Multimodal Assistant in Google Ecosystem
Google Gemini is the consumer and productivity layer built on Gemini models, available through web, mobile apps, and deeply integrated into Google Search, Gmail, Docs, Sheets, and Android. For users already embedded in Google’s ecosystem, it provides the most frictionless multimodal AI experience.
Seamless Google Workspace Integration
Upload images and documents, ask questions, and generate content with contextual awareness of your Google Drive and Gmail when you connect those services. The AI understands your files, calendar, and communication history for proactive assistance.
AI Mode in Search
Gemini-powered AI Mode analyzes queries with rich visuals and shopping data from over 50 billion product listings, delivering interactive, image-rich results that go beyond traditional search.
Personal Assistant Capabilities
The Gemini app incorporates history from Maps, Gmail, and Calendar to provide proactive reminders, trip planning suggestions, and task management integrated with your existing Google data.
Pricing Tiers
Free Gemini tier offers basic multimodal chat with limits. Gemini Advanced (AI Pro) costs approximately $19.99/month or $199.99/year, often bundled with 2TB Google One storage and access to Gemini 2.5 Pro. Premium AI Ultra tier at around $249.99/month targets power users with higher multimodal and video workloads.
Pros:
- Frictionless for Google Workspace users
- Strong everyday productivity features
- Tight integration with Gmail, Docs, Drive, and Android
Cons:
- Best value only within Google ecosystem
- Less control than direct API access
Best for: Teams and individuals already using Google Workspace extensively who want multimodal AI integrated into their existing productivity tools.
5. DeepMind Gemini 1.5+/3 Pro – Best Multimodal API for Long-Context Apps
DeepMind’s Gemini foundation models (Gemini 1.5, 2.5, and Gemini 3 Pro) are exposed via Gemini API, Vertex AI, and AI Studio, designed specifically for developers building third-party applications with text, image, audio, and video capabilities.
Massive Context Windows
Gemini 1.5 Pro and successors handle millions of tokens of interleaved text, audio, and video, with research demonstrating recall and reasoning on contexts approaching 10 million tokens. This enables analysis of entire multi-document corpora, long videos, or large codebases in single requests.
Needle-in-Haystack Performance
Internal tests show near-perfect recall (>99.7%) for locating specific information within up to 1 million tokens of multimodal content, with strong performance maintained even at 10 million tokens—outperforming earlier models like GPT-4 Turbo on similar benchmarks.
Developer-Focused Features
Available through Gemini API and Vertex AI with support for agentic workflows, function calling, and integration into generative UI platforms. Built for teams constructing production applications rather than end-user chat interfaces.
API Pricing Model
Billed per 1K tokens for text with additional per-unit charges for multimodal features. Pricing tiers adjust for long-context workloads, with 1M-token and higher context options available. Enterprise customers typically access through Vertex AI contracts aligned with broader Google Cloud commitments.
Pros:
- Best option for building long-context multimodal applications
- Excellent video and audio processing capabilities
- Tight Google Cloud and Vertex AI integration
Cons:
- Requires engineering resources and cloud infrastructure
- Closed-source with workloads tied to Google Cloud
Best for: Developers building applications that analyze long videos, multi-document corpora, or require massive multimodal context windows.
6. Meta LLaMA 3/3.2 – Best Open-Source Multimodal LLM

LLaMA 3 is Meta’s open-weight LLM family with 8B and 70B parameter models aimed at reasoning, coding, and instruction following, released under permissive licenses. LLaMA 3.2 adds multimodal capabilities with vision-language support, making it the leading candidate for “best open source multimodal llm” use cases.
Open-Weight Architecture
Developers can download, fine-tune, and deploy LLaMA models on their own infrastructure without per-token licensing fees. This includes deployment on Apple Silicon Macs, local servers, and custom cloud environments depending on parameter size and available compute.
Multimodal Capabilities in LLaMA 3.2
LLaMA 3.2 includes text+image understanding and generation for vision-language tasks like document analysis, visual search, AR applications, and content generation. Performance on standard NLP benchmarks relative to parameter size shows improved reasoning and coding skills over LLaMA 2.
Local Deployment Options
For Apple Silicon Macs (M2/M3/M4), smaller LLaMA 3.x and 3.2 variants like the 8B model run locally via Ollama (Mac-native runner) or HuggingFace Transformers with quantized weights. This makes LLaMA the answer for “best multimodal llm local apple silicon 2025” and “best multimodal llm local mac” searches.
Cost Structure
Model weights available under Meta’s license at no direct per-token cost. Operational expenses are mainly compute resources and storage for local or cloud deployment, making it extremely cost-effective for high-volume workloads.
Pros:
- Open-weight and highly customizable
- Full on-premise deployment for data-sensitive environments
- No per-token usage fees
- Growing ecosystem of fine-tuned variants
Cons:
- Requires MLOps skills and hardware to deploy and scale
- May trail frontier closed models on complex multimodal reasoning
Best for: Organizations needing on-premise AI, compliance-heavy industries, researchers wanting full model control, and teams with data sensitivity requirements that prevent cloud usage.
Multimodal LLM Comparison: Features, Pricing & Use Cases
Here’s how the top multimodal LLM solutions stack up across key parameters. SimpleChat leads in model variety and cost efficiency, making it the practical choice for most professionals.
| Solution | Best For | Multimodal Strengths | Models Available | Pricing | Deployment | Open/Closed |
|---|---|---|---|---|---|---|
| SimpleChat | All-in-one access to 10+ models | Aggregates GPT-5, Claude, Gemini, Grok, Perplexity; switch models per task | 10+ including GPT-5, Claude 4.1, Gemini 2.5 Pro, Grok 4 | ~90% cheaper than separate subscriptions | Cloud | Aggregator platform |
| GPT-5 | Advanced reasoning & code | Top MMMU scores, excellent visual-code understanding | GPT-5, GPT-5 Mini | ~$20/mo (ChatGPT Plus) + API | Cloud | Closed |
| Claude 3/4.x | Safety-critical work | Strong document analysis with safety focus, 200K context | Opus, Sonnet, Haiku | Free + $18-20/mo Pro + API | Cloud | Closed |
| Google Gemini | Google Workspace users | Gmail, Docs, Drive integration for productivity | Gemini 2.5 models | Free + $19.99/mo Advanced | Cloud | Closed |
| DeepMind Gemini 1.5+/3 | Long-context dev apps | 10M+ token context, developer API | Gemini 1.5 Pro, 3 Pro | API per-token pricing | Cloud (Vertex AI) | Closed |
| LLaMA 3/3.2 | Local/custom deployment | Open-weight, customizable, works on Apple Silicon | 8B, 70B variants | Free (compute costs only) | Local + Cloud | Open-weight |
The comparison reveals a clear pattern: SimpleChat eliminates the need to choose between models by providing access to all of them. For teams wanting to test GPT-5’s reasoning against Claude’s safety-focused analysis or Gemini’s long-context capabilities, the multi-model approach saves both money and time.
Frequently Asked Questions About Multimodal LLMs
What is the best multimodal LLM in 2025?
SimpleChat is the best multimodal LLM solution because it provides access to 10+ premium models (GPT-5, Claude 4.1, Gemini 2.5 Pro, Grok 4) through one interface at 90% lower cost than separate subscriptions. For single models, GPT-5 leads in reasoning, Claude excels in safety-critical work, and Gemini dominates long-context applications.
What is the best open source multimodal LLM?
LLaMA 3.2 is the best open-source multimodal LLM, offering vision-language capabilities with 8B and 70B parameter options that can run locally on Apple Silicon and other hardware. It’s available under Meta’s permissive license with no per-token costs, making it ideal for organizations needing full control and on-premise deployment.
What is the best multimodal llm local apple silicon 2025?
LLaMA 3.2 (8B variant) running via Ollama is the best choice for local deployment on Apple Silicon M2/M3/M4 Macs, providing solid multimodal performance while running entirely on-device. For cloud-based frontier models alongside local deployment, SimpleChat complements LLaMA by providing access to GPT-5, Claude, and Gemini.
How much can I save with SimpleChat vs separate AI subscriptions?
Individual subscriptions to ChatGPT Plus, Claude Pro, and Gemini Advanced cost $110+/month combined. SimpleChat consolidates access at approximately 90% lower cost, translating to annual savings of around $1,188 per professional. The platform serves over 12,500 professionals who’ve made this switch.
Can I use multiple multimodal LLMs for the same task?
Yes, and this is SimpleChat’s key advantage. You can test the same prompt across GPT-5, Claude, Gemini, and other models to identify which gives the best output for your specific use case. This comparative testing approach would cost hundreds monthly through separate subscriptions.
What is the best multimodal llm huggingface?
LLaMA 3.2 is widely available on HuggingFace and represents the most popular open-weight multimodal model for developers wanting to fine-tune or deploy custom solutions. The platform hosts various quantized versions optimized for different hardware configurations, from consumer GPUs to enterprise servers.
Get Started with the Best Multimodal LLM Solution Today
Multimodal LLMs in 2025 combine text, vision, audio, and code capabilities that replace multiple specialized tools. Leading solutions include GPT-5 for reasoning, Claude for safety-critical work, Gemini for ecosystem integration, and LLaMA 3.2 for open-source flexibility.
The smartest approach for most professionals: SimpleChat provides access to 10+ premium models through one interface. Instead of paying $110+/month for separate subscriptions, you get approximately 90% cost savings—translating to roughly $1,188 in annual savings. Over 12,500 professionals already trust the platform for daily AI workflows.
Stop paying for multiple AI subscriptions. Access GPT-5, Claude 4.1, Gemini 2.5 Pro, Grok 4, Perplexity, and 10+ other multimodal models in one place with SimpleChat →
Join thousands of professionals simplifying their AI workflows. Try SimpleChat today →
Leave a Reply